Hagelloch Measles – Fitting a Stochastic SIR Grouped Model
Source:dev/vignettes/not-built-vignettes/hagelloch-sir-stochastic-three-groups.Rmd
hagelloch-sir-stochastic-three-groups.RmdOverview
In this series of vignettes, we will demonstrate epidemic analysis pipeline from EDA to dissemination using a case study of measles.
Hagelloch series vignettes
Hagelloch 1 Pre-processing and EDA
Hagelloch 2.1 Modeling and Simulation: the SIR model
Hagelloch 2.2 Modeling and Simulation: fitting a SIR model
Hagelloch 2.3.1 Modeling and Simulation: a stochastic SIR model
Hagelloch 2.3.2 Modeling and Simulation: a stochastic SIR model
Goals in this vignette
Look at a three-group model
Derive the likelihood
Find parameters that maximize the likelihood for the Hagelloch data.
Simulate SIR models from the best fit model
Previously we saw that the classes of children may have different SIR curves. We can model this in a number of ways: one being to partition the children into three separate groups of susceptibles. These susceptible children in classes Pre-K, first, and second class have rates \(\beta_0\), \(\beta_1\), and \(\beta_2\) rates of becoming infectious. The children still all share the same rate of recovery, \(\gamma\).
This model can be described with five states: \((X_0, X_1, X_2, X_3, X_4) = (S_0, S_1, S_2, I, R)\) and the following equations
After loading the libraries,
library(tidyverse) library(EpiCompare) library(knitr) library(kableExtra) library(RColorBrewer) library(deSolve)
we get the aggregate SIR data from hagelloch_raw and define our deterministic, continuous time SIR model.
## Getting aggregate data aggregate_hag <- hagelloch_raw %>% mutate(class = ifelse(CL == "1st class", 1, ifelse(CL == "2nd class", 2, 0))) %>% group_by(class) %>% agents_to_aggregate(states = c(tI, tR), min_max_time = c(0, 55)) %>% rename(time = t, S = X0, I = X1, R = X2) %>% tidyr::pivot_wider(id_cols = time, names_from = class, values_from = c(S, I, R))
sir3_loglike <- function(par, data){ data$beta00 <- par[1] data$beta01 <- par[2] data$beta02 <- par[3] data$beta10 <- par[1] data$beta11 <- par[2] data$beta12 <- par[3] data$beta20 <- par[1] data$beta21 <- par[2] data$beta22 <- par[3] data$gamma <- par[4] data$N <- data$S_0 + data$S_1 + data$S_2 + data$I_0 + data$I_1 + data$I_2 + data$R_0 + data$R_1 + data$R_2 data_new <- data %>% dplyr::mutate( prev_S0 = dplyr::lag(S_0), prev_S1 = dplyr::lag(S_1), prev_S2 = dplyr::lag(S_2), prev_I0 = dplyr::lag(I_0), prev_I1 = dplyr::lag(I_1), prev_I2 = dplyr::lag(I_2), prev_R0 = dplyr::lag(R_0), prev_R1 = dplyr::lag(R_1), prev_R2 = dplyr::lag(R_2), ) %>% dplyr::mutate( delta_S0 = S_0 - prev_S0, delta_S1 = S_1 - prev_S1, delta_S2 = S_2 - prev_S2, delta_I0 = I_0 - prev_I0, delta_I1 = I_1 - prev_I1, delta_I2 = I_2 - prev_I2, delta_R0 = R_0 - prev_R0, delta_R1 = R_1 - prev_R1, delta_R2 = R_2 - prev_R2 ) %>% dplyr::mutate( prob_inf0 = (beta00 * I_0 + beta01 * I_1 + beta02 * I_2) / N, prob_inf1 = (beta10 * I_0 + beta11 * I_1 + beta12 * I_2) / N, prob_inf2 = (beta20 * I_0 + beta21 * I_1 + beta22 * I_2) / N ) %>% dplyr::mutate( loglike_SI_init0 = (-delta_S0) * log(prob_inf0) + S_0 * log(1 - prob_inf0), loglike_SI_init1 = (-delta_S1) * log(prob_inf1) + S_1 * log(1 - prob_inf1), loglike_SI_init2 = (-delta_S2) * log(prob_inf2) + S_2 * log(1 - prob_inf2), loglike_SI0 = ifelse(prob_inf0 %in% c(0, 1), 0, loglike_SI_init0), loglike_SI1 = ifelse(prob_inf0 %in% c(0, 1), 0, loglike_SI_init1), loglike_SI2 = ifelse(prob_inf0 %in% c(0, 1), 0, loglike_SI_init1), loglike_IR = (delta_R0) * log(gamma) + (prev_I0 - delta_R0) * log(1 - gamma) + (delta_R1) * log(gamma) + (prev_I1 - delta_R1) * log(1 - gamma) + (delta_R2) * log(gamma) + (prev_I2 - delta_R2) * log(1 - gamma), loglike = loglike_SI0 + loglike_SI1 + loglike_SI2 + loglike_IR ) %>% dplyr::filter(time != 0) return(sum(data_new$loglike)) }
init_params <- c(.5, .5, .5, .1) test <- sir3_loglike(init_params, data = aggregate_hag) best_params <- optim(par = init_params, fn = sir3_loglike, control = list(fnscale = -1), # switches from minimizing function to maximizing it data = aggregate_hag, hessian = TRUE, method = "L-BFGS-B", lower = .01, upper = .999) print(best_params$par, digits = 2)
## [1] 0.75 0.42 0.01 0.13Simulating new outbreaks
Now that we have the best (point) estimate for \(\beta\) and \(\gamma\), we can simulate new data.
set.seed(2020) ## This is the SIR representation trans_mat <- matrix("0", byrow = TRUE, nrow = 9, ncol = 9) trans_mat[1, 1] <- "X0 * (1 - (par1 * X3 + par2 * X4 + par3 * X5) / N)" ## S0 -> S0 trans_mat[1, 4] <- "X0 / N * (par1 * X3 + par2 * X4 + par3 * X5)" ## S0 -> I0 trans_mat[2, 2] <- "X1 * (1 - (par1 * X3 + par2 * X4 + par3 * X5) / N)" ## S1 -> S1 trans_mat[2, 5] <- "X1 / N * (par1 * X3 + par2 * X4 + par3 * X5)" ## S1 -> I1 trans_mat[3, 3] <- "X2 * (1 - (par1 * X3 + par2 * X4 + par3 * X5) / N)" ## S2 -> S2 trans_mat[3, 6] <- "X2 / N * (par1 * X3 + par2 * X4 + par3 * X5)" ## S2 -> I2 trans_mat[4, 4] <- "X3 * (1 - par4)" ## I0 -> I0 trans_mat[4, 7] <- "X3 * (par4)" ## I0 -> R0 trans_mat[5, 5] <- "X4 * (1 - par4)" ## I1 -> I1 trans_mat[5, 8] <- "X4 * (par4)" ## I1 -> R1 trans_mat[6, 6] <- "X5 * (1 - par4)" ## I2 -> I2 trans_mat[6, 9] <- "X5 * (par4)" ## I2 -> R2 trans_mat[7, 7] <- "X6" ## R0 -> R0 trans_mat[8, 8] <- "X7" ## R1 -> R1 trans_mat[9, 9] <- "X8" ## R2 -> R2 rownames(trans_mat) <- c("S_0", "S_1", "S_2", "I_0", "I_1", "I_2", "R_0", "R_1", "R_2") init_vals <- c(90, 30, 67, 0, 0, 1, 0, 0, 0) par_vals <- best_params$par max_T <- 55 n_sims <- 500 abm <- simulate_agents(trans_mat, init_vals, par_vals, max_T, n_sims, verbose = FALSE) grouped_agents <- abm %>% tidyr::pivot_longer(cols = -c(sim, agent_id), names_to = c(".value", "group"), names_sep = "_") %>% filter(!(is.na(S) & is.na(I) & is.na(R))) agg <- grouped_agents %>% group_by(sim, group) %>% agents_to_aggregate(states = c(I, R))
## TODO ## geom_prediction_band problem?? obs_groups <- hagelloch_raw %>% mutate(class = ifelse(CL == "1st class", 1, ifelse(CL == "2nd class", 2, 0))) %>% agents_to_aggregate(states = c(tI, tR), min_max_time = c(0, 55)) %>% rename(time = t, S = X0, I = X1, R = X2) ggplot() + geom_prediction_band(data = agg, aes(x = X0, y = X1, z = X2, sim_group = sim), alpha = .5, conf_level = .8, fill = "orange") + coord_tern() + theme_sir() + geom_point(data = obs_groups, aes(x = S, y = I, z = R))
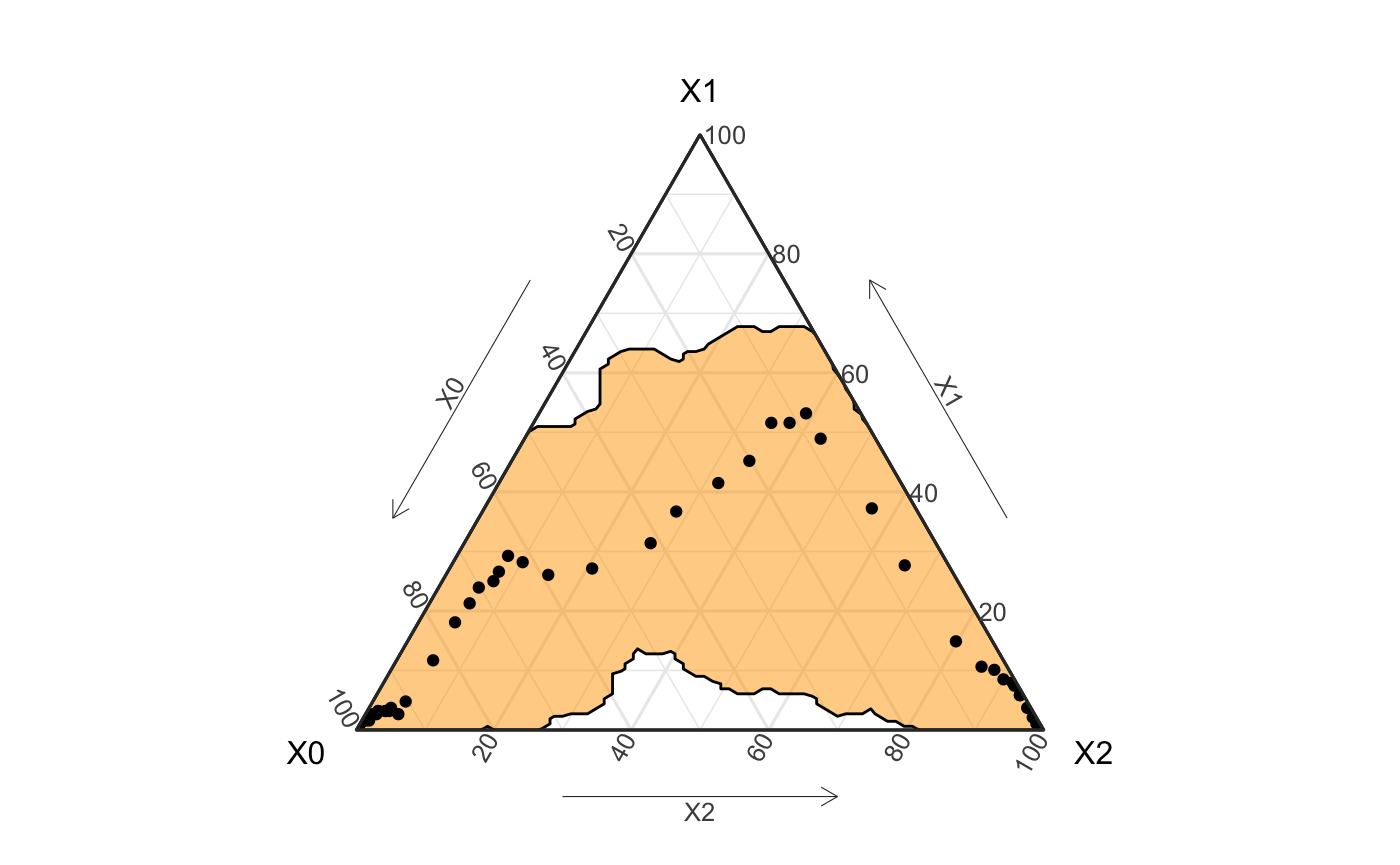
labs(title = "Prediction band for best parameters and original data")
## $title
## [1] "Prediction band for best parameters and original data"
##
## attr(,"class")
## [1] "labels"obs_groups <- hagelloch_raw %>% mutate(class = ifelse(CL == "1st class", 1, ifelse(CL == "2nd class", 2, 0))) %>% group_by(class) %>% agents_to_aggregate(states = c(tI, tR), min_max_time = c(0, 55)) %>% rename(time = t, S = X0, I = X1, R = X2) grouped_agents <- abm %>% tidyr::pivot_longer(cols = -c(sim, agent_id), names_to = c(".value", "group"), names_sep = "_") %>% filter(!(is.na(S) & is.na(I) & is.na(R))) agg <- grouped_agents %>% group_by(sim, group) %>% agents_to_aggregate(states = c(I, R)) ggplot() + geom_prediction_band(data = agg, aes(x = X0, y = X1, z = X2, sim_group = sim, fill = group), alpha = .5, conf_level = .95) + coord_tern() + theme_sir() + geom_point(data = obs_groups, aes(x = S, y = I, z = R, col = factor(class))) + labs(title = "Prediction band for best parameters and original data")
